Aerospike-SSD存储块结构
BLOCK结构
注意以下内容以3.15版本为基准,新版AS可能会有所不同
我们经常说Aerospike专门针对SSD做了系统性适配和优化,那么最直接的问题便是AS究竟是如何在SSD上存储数据。
带着这个疑问开始分析源码,主要代码位于drv_ssd.c
核心数据结构是drv_ssd_block和drv_ssd_bin(结构定义位于drv_ssd.h),前者表示单条记录对应的SSD存储块,本身是一个变长的结构体,后者表示单条记录中的一个BIN
很显然可以看到单条记录的所有BIN都是紧凑排布在一起的,一图胜千言,如下所示
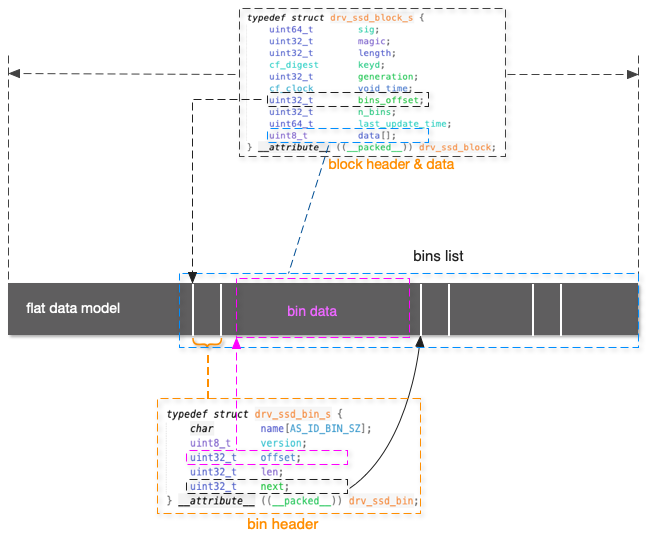
- block的bin_offsets指向bins起始偏移
- block的n_bins记录总共有多少bin
- bin的offset指向原始数据的起始偏移
- len记录当前bin原始数据长度
- next指向下一个bin的起始偏移
可以看出bins几乎是一个扁平的链表,无法支持随机查找
需要注意每个drv_ssd_block结构体的最大长度不可超过预设的write-block-size值,在这个版本该值最大为1M,在4.x版本最大则为8M
每个drv_ssd_block写入磁盘时均按MIN_IO_SIZE的整数倍对齐,MIN_IO_SIZE一般为512字节(跟存储设备的逻辑扇区大小一样),
但某些设备的逻辑扇区和物理扇区大小并不一致,后者远大于前者,这将是一个潜在的性能风险
AS节点在冷启动时会扫描SSD上所有的记录并据此构建内存中的主索引(参考上面一篇文章)
序列和反序列化
下面将简述AS如何序列化和反序列化(或许应该换个词语,AS里叫FLAT)不同类型的BIN,AS把BIN的数据称作Particle
每读到一个BIN时AS会根据BIN DATA的第一个字节来判断类型,例如STRING/BLOB等,解析逻辑位于particle.c的safe_particle_type函数
然后从一个事先构建好的particle_vtable中找到相应类型的转换函数指针并调用,这里其实是用C实现了一个近似的多态模式,较为简洁而巧妙;
这些多态函数分别位于不同的模块,以particle_开头的文件中,目前支持的主要有blob/float/geojson/integer/list/map/string
而写入时流程则更为复杂,AS并不是每一条记录都会写磁盘,而是首先将记录放入到一个缓冲区即ssd_write_buffer,简称swb,然后在一定条件下(例如缓冲区满了)再将swb刷写到SSD上,换句话说,相邻时刻的短数据大概率会在同一个swb中(刷到SSD的时候也是紧凑相邻的);这样做的好处显而易见,可以很好的降低设备的IOPS并最终提升性能
特别注意的是如果当前待写入的记录大小已经超过swb的剩余空间,则AS会将当前这个swb送入flush等待队列,然后分配一个新的swb;如果这个等待队列过长则AS会抛出DEVICE OVERLOAD异常
typedef struct {
cf_atomic32 rc;
cf_atomic32 n_writers;
bool skip_post_write_q;
struct drv_ssd_s *ssd;
uint32_t wblock_id;
uint32_t pos;
uint8_t *buf;
} ssd_write_buf;
swb的大小不得超过write-block-size(没错,又一次涉及到这个配置),这个值应配置为多少是一个玄学问题,每个厂商每个型号的SSD都可能有差别,这也就是为什么建议事先跑一次ACT测试以便获取真实情况
随着不同长度的记录的不断插入和更新,SSD上将存在大量数据碎片和空洞,AS会在后台持续运行碎片整理(这个跟SSD固件内部的碎片整理没有任何关系),本文不做展开