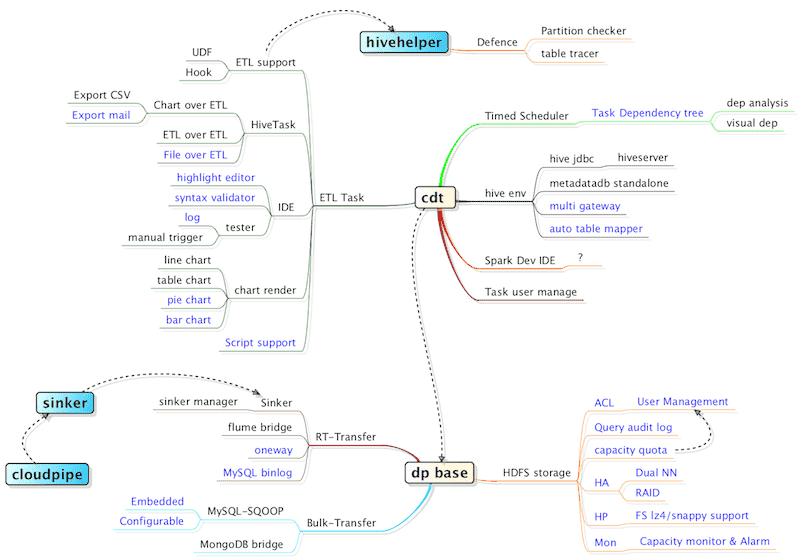
堆糖数据平台核心与规划
互联网公司业务一般发展都非常快,迭代周期相对传统行业而言都非常短;从一个大的方面来思考现状,很多业务逻辑本质上无非是对数据进行查询、过滤和转换,这些逻辑本身占用项目大量时间和精力,并且随着产品本身的周期演进,逻辑可能会频繁变动和调整,开发工程师不得不疲于应对重复而枯燥的工作,久而久之会降低团队整体的效率和士气。
当然这里提到的主要是非实时数据,事实上通过定量梳理会发现业务系统中真正要求实时的部分并不多,也就意味着相当一部分可以离线去做。
除了业务逻辑,系统层面也存在大量类似的需求,例如监控和性能分析,它们都是需要大量的数据支撑;缺乏数据支撑的系统将如同空中楼阁,毫无意义。
回到行业上来讲,互联网公司如果对自己的用户们是怎么访问,在哪里停留,对什么感兴趣等等这些情况一无所知的话那么这个公司将难以发展下去,数据已经逐渐成为公司最重要的资产之一(或许这里没有之一)。经济学上有一经典理论,如果没有流通性,钱将失去其价值。这一点拿到数据上也是可以讲的通的,如果仅仅是类似于收集癖般的收集各类数据,则无法创造出任何价值。
所以无论公司规模如何,都需要思考如何能将数据利用好,使其能成为产品和运营的核心推动力和决策依据。
因此体系化和系统化的思考规划是必不可少的,很多开发工程师在具体的某个点上可能拿的非常准,但是一旦上升到更为宏观的层面上就显得手足无措。这个时候对架构的要求就比较高,不能在后期出现颠覆性的错误,否则将会给公司带来较大的损失。
平台化
体系化的规划通常产出结果是平台化。所谓平台定义,即预设的环境+基础组件+边界和约束,并对上层应用提供功能支撑。
回到数据上来分别阐述这几个定义:
预设环境:包括数据存储环境和计算环境。
在现在这个开源的时代很多事情已经不用我们过多操心,例如hadoop体系,成熟稳定并在业内大规模运用,作为存储这似乎是不二之选。计算也是一样,以YARN MR计算模型为主,对于机器学习类等需要反复迭代的任务,则采用SPARK;SPARK和YARN都能够非常方便快捷的与HDFS对接。
基础组件:采集、传输、清洗过滤载入、转换、提取、辅助。
大规模的数据采集方案不多,例如flume和kafka,flume的好处是只需要通过编写配置文件即可完成采集和传输。看起来这是一个十分完美并且低成本的方案,但是在评估过程中我们发现有这样几个问题: 1,flume配置文件语法诡异容易出错并且不易排查; 2,当前对动态载入配置支持不好,经常出现卡死状况,必须杀掉重启解决; 3,flume对环境有依赖,主要是依赖Hadoop相关的环境变量和Lib;
而kafka则没有这类问题,虽然比起flume来说kafka有一定的代码开发成本。 性能上kafka和flume都是没有问题,可以支撑极高的数据量(具体数值这里就不贴了); 扩展性上kafka有先天优势,可以嵌入业务系统代码,也可以独立作为组件运行; 稳定性上显然也是kafka更胜一筹;
综合这样几点来说,最终选择Kafka作为采集和传输核心。 为了给应用提供快速接入,提供了一套sinker机制,下面会有详细描述。
提取、转换、载入,也就是俗称的ETL。Hadoop生态链中最著名的莫过于Hive,可以通过编写HQL语句实现各类复杂逻辑的数据处理,这是整个平台最核心的系统基础设施。Hive拥有非常高的可扩展性,可自行开发UDF实现复杂逻辑,以及Hook来进行审计和追踪。
边界:该平台与其它业务系统的切入点,以及相互之间的沟通方式。
数据平台如何与外部各种复杂异构的业务系统集成?这是十分核心的问题。 这里其实不应该过多思考非平台本身的东西,因为外部系统是不可控的,无论做出什么样的设计,总会存在少数不能直接满足的地方。数据平台的核心是数据,因此很自然的,其边界就是数据集(dataset)本身,外部系统将数据集输入到平台,并以类似的方式从平台取到目标数据集。
约束:什么样的数据可以进到这个平台;平台能够提供的服务能力等。
前面提到,这里的数据一般是非实时数据。规划上平台不支持实时的数据处理。并且数据本身一定是结构化可枚举的,也就落地的讲,元数据是确定的(而不是不可变的)。
功能:平台对外提供的功能的准确定义。
1,数据基础功能,包括但不限于采集存储转换 2,数据任务驱动 3,安全权限控制 4,监控告警机制
整体结构
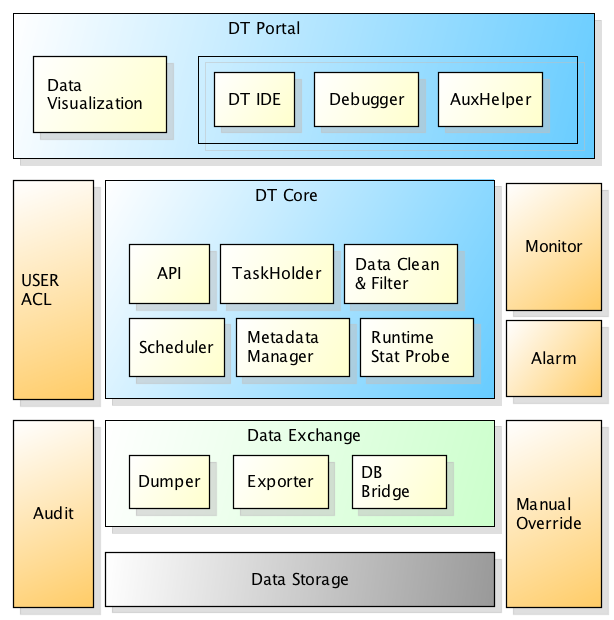
核心理念
数据任务(DataTask,DT)
定义:进行数据处理的一组逻辑实体。 运行方式:系统调度和人工触发。 逻辑承载体:HiveQL。
每个DT可以拥有多个HiveQL语句,因而可以实现相当复杂的逻辑。
这里存在一个调度的问题,想像当前有多个DT,其中某些DT依赖另外几个DT生成的表,为了让这些DT都能够顺利执行,系统必须计算这些DT之间的依赖关系,并依次调度执行。
任何一个DT,其必定依赖某些表,称之为输入; 也可能会产生某些表,称之为输出; 因此反复迭代待执行的DT集合,一旦发现某个DT的输入条件都已满足,则运行之。
技术上可以通过解析HiveQL语法树实现。
为了给上层提供丰富的功能,DT本身有多种类型,如ETL DT,Chart DT,前者就是普通的ETL任务。后者则是运营和产品高度依赖的图形化报表,它们两者本质上没有什么区别,只是一个会将数据输出为可视化结构。虽然看起来这两件事情风马牛不相及,但在这里基于平台化思想,两者完美统一。
既然是任务,就表明它是在后台默默运行,这里潜在问题就是它不像前台业务系统一样容易被感知和监测。换句话说任务的运行状态需要完善的监控和日志记录,一旦出现问题就需要采取预先设定的应急方式来处理,如给管理员发送警报、自动重跑等。
每个DT运行的元数据(如开始结束时间、触发者、异常堆栈)都会记录在数据库中,并提供界面供查询分析用。DT开发者也可以定义异常邮件列表,一旦发生异常则立刻发送告警邮件)
数据任务职责边界
这里说的职责,是指人的职责,也就是DT任务的开发者和下游用户。很显然一般的DT是由ETL工程师和BI来编写,他们需要关注的点就是逻辑本身,编写的就是单纯的HiveQL。
下游用户一般除了他们自身,还有产品运营的日常报表查阅等。还有业务开发,也是潜在的下游用户。因为线上的服务可能会依赖于这些任务的产出数据。
基于这样几点出发我们确定了以下几个数据任务类型。
数据任务类型
基线任务
顾名思义基线就是被其它任务所依赖的任务,基线任务一般都是公司内部重要的基础数据任务,需要额外的关注。每个基线都需要有专人负责把关,一旦出现问题该责任人要在第一时间内给出解决方案并通知给下游用户。
凡依赖于基线的任务必须在基线成功执行后才能调度。
报表任务
数据报表是重要的决策工具,在公司发展早期,大量报表都是开发人员自行定制开发而成,并且形式各样,可能是某种脚本,甚至是直接嵌入在生产系统里面的一个模块,随着各类报表任务增多,这些分散在各处的任务会成为难以维护的烫手山芋,而且由于缺乏统一的规范和流程,导致后期新报表的越来越占用开发资源。
回想一下之前的报表开发流程:从数据库查出各种数据,调用某个接口获取另外一些数据,以某种逻辑对这些数据进行转换处理,将最终结果传递到目标。
按照本文开头的想法,这些形态各异的报表开发流程是可以,也是必须统一的。 因此数据平台的一个重要组成部分就是报表系统。
这个系统提供以下这些功能: * 图形化报表渲染,例如折线图、饼图、表格 * 报表数据导出和订阅
数据回流任务
业务系统会用到数据任务的结果数据,这就表明离线会影响到在线。说的更明确一点就是数据任务会将数据通过某种方式回流到在线数据库,这就是所谓的回流任务。
在Hadoop+Hive这个体系内有众多的开源框架可以做到这一点,根据数据库类型的不同,例如MySQL对应的有Sqoop,Mongo对应的有Mongo-Hadoop组件。
但这个事情没有这么简单,并不是把数据一股脑的塞到线上库就行了。要考虑到因为这是线上数据库,所以是用户能够直接访问到的,也就是说这些库的可用性直接影响到线上系统本身的可用性。
以mongoDB为例,当大规模数据插入的时候mongo的锁会大大增加,从而导致查询性能急剧下降。因此回流任务要特别注意回流过程的可控性,一定需要提供介入机制来控制导入速度和频率。
还是以mongo为例,其有一个开源组件Mongo-Hadoop,可以直接将mongo的表映射到Hive中,可以像普通Hive表一样操作,并且还能直接insert,但是其没有提供速度控制功能,因此需对其进行改造,加入此功能(这个在github上,https://github.com/kevx/mongo-hadoop/tree/0602)。
部分关键技术
sinker体系
sinker是一套基于Kafka的数据收集系统,开发人员在管理平台上配置业务代号,然后由运维分配HDFS存储集群和Kafka集群,业务系统只需要引用预先开发好的SDK,即可将数据传递到最终的存储。整个过程对应用入侵很小,而且随着业务量扩大,运维可动态调整sinker对应的存储集群等,整个系统可轻松实现水平扩展。
如何实现动态调整? 这里的关键在于,每个sinker的配置存储在公司内部的公共ZK配置集群,客户端每次都会从这里读取相关配置并做相关处理。
而每个业务的sinker是独立进程运行,由中央协调器负责启动和监视,因此业务与业务之间不会产生关联影响,整个系统稳定性非常高。
有的人可能发现中央协调器是一个单点,其实不是这样;协调器是一个普通的Java项目,并且在多台机器上有运行实例,这些多个实例之间采取ZK分布式锁来竞争主从。
路线规划与演进