高速存储设备与混合内存架构模型
大背景
工业界在闪存存储领域进展较快,各类新产品层出不穷,单盘随机IOPS普遍能达到700K以上, 最新的高端NVMe甚至能达到百万IOPS级别,给应用带来无穷无尽的可能
伴随着IOPS的提升,存储与传统DRAM之间的界限开始变得微妙,如下图所示
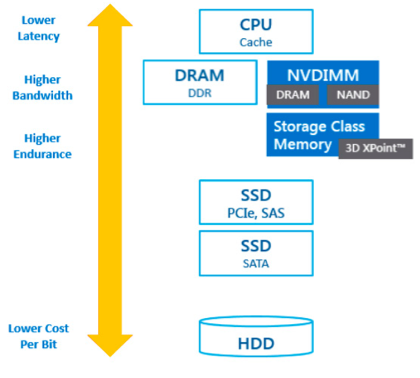
促使很多架构师开始思考一个问题:
是否有可能将这两种存储介质融合在一起并对上层应用提供一致性的内存视图
传统堆管理模型
MALLOC系
符合POSIX标准的堆内存管理,大部分应用都使用这种方式,简单易懂通用性好,无需关心底层分配细节,只需要专注在分配和释放这两个入口即可
malloc通常由glibc实现,一些先进的公司或组织也提供了另外的实现,如jemalloc和Google的tcmalloc(后者已经停止维护)
malloc是以arena+chunk方式管理内存,数据结构和算法参考 https://sourceware.org/glibc/wiki/MallocInternals
无论是哪种实现,具体的算法复杂性都较高,这里不做展开
从OS层面来看,malloc最终会使用sbrk系统调用完成虚拟地址空间的分配,OS会创建页表映射关系和权限位设置, 这个过程用户无法干预,用户无法指定或预测分配的虚拟地址,也无法控制虚拟地址空间映射到物理内存的什么地方
MMAP系
Linux/UNIX提供了MMAP机制,更加灵活且强大,也是一种常用方式,支持PRIVATE和SHARED模式
前者需要占用私有物理内存空间且不可DROP,一旦导致物理内存耗尽就会被OS KILL, 后者则是按Page Cache方式管理,OS将负责具体的DROP策略
mmap好处在于用户可以向OS“建议”目标区域的虚拟地址,一般来说该建议一定会被“采纳”,尤其是对于高地址空间
最新的JDK17 ZGC即采用这种方式,虚拟地址固定分配在4TB-20TB的地址区间内,每个区间固定4TB大小
mmap缺点在于在建立大量映射区域的时候性能有严重问题,每次mmap时会在内核中维持一个vm_area_struct描述符
每个vma相互之间以链表形式关联,如下图所示
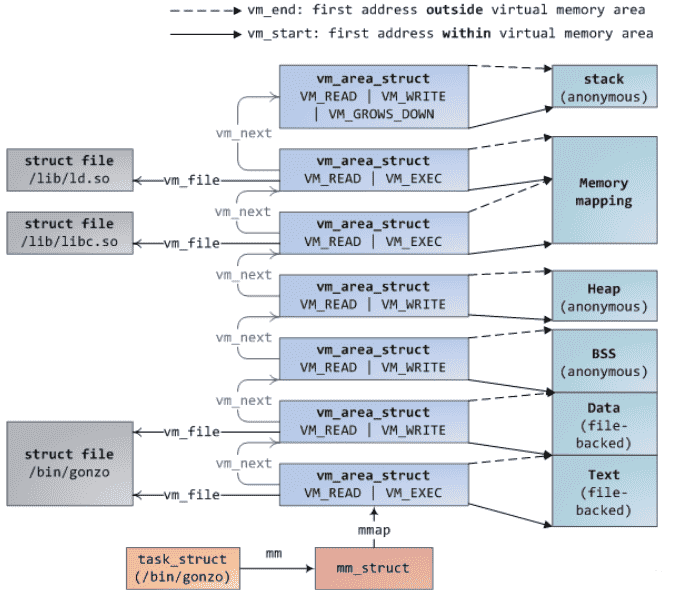
同时还有额外的树结构(都需要消耗宝贵的内核资源)以加速查找
若mmap的越多,额外消耗的内核内存就越多,查找时间越长,系统整体性能越差
SHM系
严格来说这并不是一种堆管理机制,Shared Memory功能有着悠久的历史,Linux提供了一套良好的API和命令行工具供开发使用
shm挂载在/dev/shm设备上,默认情况下容量为物理内存的一半,且其数据在机器重启前可持续保存,不会随着应用程序重启而消失, 在某些场景下这可能大有可为
shm可分段管理,称为segment,最大支持4096个,每个seg拥有独立的权限配置和容量
应用程序可在运行时将某个seg动态attach到当前应用的地址空间(也可以指定目标虚拟地址)
传统模型挑战
这里的困难在于应用程序无法把存储设备当作内存使用,因为访问IO设备和DRAM是完全不同的两种路径,外部存储设备不可直接寻址
CPU通过单条指令即可直接访问DRAM,所谓的LOAD/STORE指令,x86上一般是指MOV
但访问IO设备必须通过其它机制,如IOPORT、DMA(现代IO的基石)等, CPU并不知道自己如何与这些由各种厂商制造的复杂IO设备进行交互,IO流程控制权会交给相关控制器负责
如最常见的SATA-AHCI控制器,CPU通过某种总线协商或约定的内存映射IO寄存器(memory mapped registers)与控制器通信
在过去很长时间,系统程序员不得不在IO设备与DRAM的鸿沟之间反复抉择并选择适当的架构和配置, 它们并不能全场通用,不同的场景甚至不同的设备型号都可能大相径庭,开发难度和成本较高
考虑到Memory Management (MM) 是现代OS中最核心最复杂的子系统之一,且与CPU架构密切相关,对研发的挑战极大 甚至市场上都很难找到能够充分理解该领域的工程师,让研发直接与这些系统打交道是几乎不可能的事情
大多数应用层开发语言或框架也未能及时跟进业界最新发展趋势,尽管硬件发展一骑绝尘,普通软件和工程师只能望其项背, 成本和效能并未随着硬件升级而相应提升
新模型
MMAP+
仍然以mmap为核心,但跟某种堆管理框架如jemalloc结合起来,将目标设备映射到虚拟地址空间,并使堆管理框架从特定区域分配堆空间
Filesystem并不是必须的,应用可以直接使用块设备读写如/dev/sda,减少中间链路的性能损耗
很多应用都支持这种方式,不需要重写整个内存管理逻辑,对上层代码几乎透明,无需关心所分配的内存背后是什么
缺点在于性能依赖PageCache,对盘的压力极大,全靠随机IO来扛,在某些场景下会有较大抖动
淘汰机制几乎不可控,但Linux仍然提供了madvise,可以实现部分”可控“
DAX
即Direct Access,不再在内核中维持PageCache而是将设备直接映射到用户空间,避免一次内存拷贝过程
内核(≥ 5.8以上版本)对该特性的开发和支持主要由Intel等公司实现,截至目前仍然处于experimental状态
在受支持的内核上,使用特定的参数挂载高速设备,同时需要启用支持DAX的FS如XFS等,EXT4也支持, 通常DAX需要和mmap结合使用,但应用需要传入特定参数,且文件元数据的可见性是一个挑战
DAX从某种程度上跟Direct IO(有很多名字DIO、O_DIRECT)较为相似,都是绕过了内核中冗长的IO Path和Cache以提高综合性能
DIO的缺点在于不支持Byte-Range方式读写,因为块设备每次读写都必须以该设备的扇区大小为单位,哪怕应用只需要1个字节,这个值通常是512字节