JVM非典型堆外内存问题分析
我们经常谈到堆外内存,许多人误以为堆外内存全部都是同一种类型的东西,然而事实上存在着多种类型,每种类型的管理方式是完全不同的。此外,这里说的堆一般是指Java堆,但是别忘了,JVM是一个C++程序,它本身也有自己的堆,Java的堆外其实可以看作是JVM的堆内,但并不完全相等。以下内容均基于OpenJDK 8u341版本。
Direct Memory
最常见的一种堆外内存,一般可通过java.nio.ByteBuffer#allocateDirect来分配,这种堆外从某种程度上说是受JVM管理的,可在启动参数中加入-XX:MaxDirectMemorySize来限制其可用的容量大小,如果不加则默认跟Xmx一致。
Metaspace
其实metaspace也是堆外内存的一种,但非常容易被人忽视。metaspace并未分配在常规的Java堆中,而是一块独立的内存区间,默认是无限大小,不过很容易通过参数做限制,其当前容量也可以非常方便的通过jstat查看。
Unsafe Allocation
一些中间件框架大量用到unsafe类,从某种程度上说这个才算得上是真正的堆外内存,可像C++一般操作内存地址以读写数据,正如其类名,它并不是一个“安全”的功能,用户必须仔细处理内存分配和释放逻辑,如果忘记释放则会产生不可恢复的内存泄漏。Unsafe类有个好处在于其底层实现里有NMT的埋点。我们可在Java进程启动参数中加入-XX:NativeMemoryTracking=detail开启追踪。注意开启后会有10%性能损耗。
一旦开启后可通过jcmd来查看堆外内存的分配报告和统计数据。一般来说大部分堆外问题在这一步都可以搞定。但如果没有那么事情就会变得复杂起来,此时就需要抛开Java体系,从OS视角去分析问题。
JVM Inner
首先我们要知道JVM在运行过程中需要大量动态分配内存,尤其是jit子系统更是如此。作为一个典型的C++应用,JVM的内存分配也遵循C++的常规做法:大部分malloc加上少部分mmap,后者的问题很好排查,因为每次mmap都会创建一块anon匿名内存区间,pmap中一览无余,还可以通过strace来跟踪mmap的调用路径。考虑到JVM本身的成熟度,由于其自身存在BUG而导致发生内存问题的概率并不会特别大。
一些三方工具,尤其是压缩类工具会在客户端中使用JNI,而JNI本质上就是一个动态链接库,直接加载到JVM进程的内存空间中执行,很显然这些动态库也会大量使用内存分配,大概率也是malloc。
在Linux上malloc默认由glibc实现,其实它的底层也是mmap。这里有一个非常经典的glibc 64M问题,即在进程的pmap内存区域列表中存在大量大小固定为64M的匿名映射区间(anon),原因是glibc为了降低线程分配内存时的竞争而为每个线程都创建一个独立的arena,但在一开始仅仅是建立映射而未commit状态,其RSS都是0。
这个问题很好解决,只需要在Java启动前设置环境变量MAX_MALLOC_ARENA=1即可,这样一来pmap中就会看到1个大的映射区间,所有线程共用。
这里面最难以分析的其实还是这些动态库内部的内存分配,因为它分配在JVM的堆中,跟jit啥的混在一起,出现问题也难以排查。这个问题可以简化为:如何在JVM中追踪malloc的调用及其来源。
Malloc Profiling
从汇编角度来说,上游应用会使用call指令跳转到malloc,CPU在跳转前会将当前指令地址EIP寄存器压栈,因此我们总是可以从栈中拿到上游来源,如果再结合一些符号信息其实就可以构建出一副调用图链,当然这里处理逻辑还是比较复杂的,没有人会手动做这些事情。
目前市面上带malloc profiling功能的库有不少,比如jemalloc就有。按照官方构建手册进行编译并在LD_PRELOAD环境变量中加入编译好的库文件路径,同时需配置MALLOC_CONF环境变量开启profiling采集,具体的操作细节这里不再赘述请参考官方文档。
jemalloc会将采样数据写在用户指定路径,然后我们就可以通过jemalloc自带的jeprof工具来构建调用图,当然也直接以文本方式输出到控制台。需要注意的是在容器环境下,如果用户在宿主机进行分析,请确保两者的C库(以及一系列的其它库)和JDK完全一致,路径也要一致,否则将会我们将无法看到任何符号,裸汇编几乎无法分析。
Dynamic Code
JVM的特殊之处在于,它的可执行代码内存区间并不一定映射在具体的可执行文件上(如elf/so),而是在运行时动态生成,也就是在pmap中只能看到一块带"x"的anon内存。这给问题排查带来了巨大的困难,好在JVM毕竟是个开源软件,可以从其源码入手来寻找它动态代码创建的规律。
以最近遇到的一个问题为例,一个Spark程序因为占用内存过高在K8S环境中迅速被Kill,我们可以看到其JVM进程的内存情况如下:
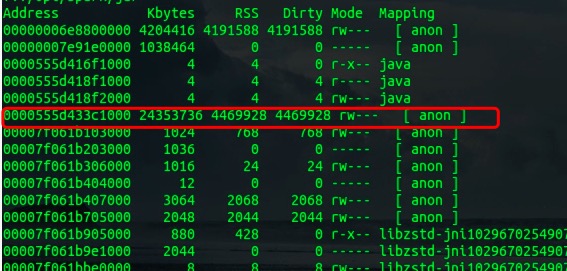
其中,最顶部这个起始地址0x6e8800000,长度1009e0000的地址区域为Java堆空间,大小正常符合预期。而下面的红框中的区域是真正的问题所在,通过gdb看到它正是JVM的堆。
经过profiling后我们得到了如下的调用图:
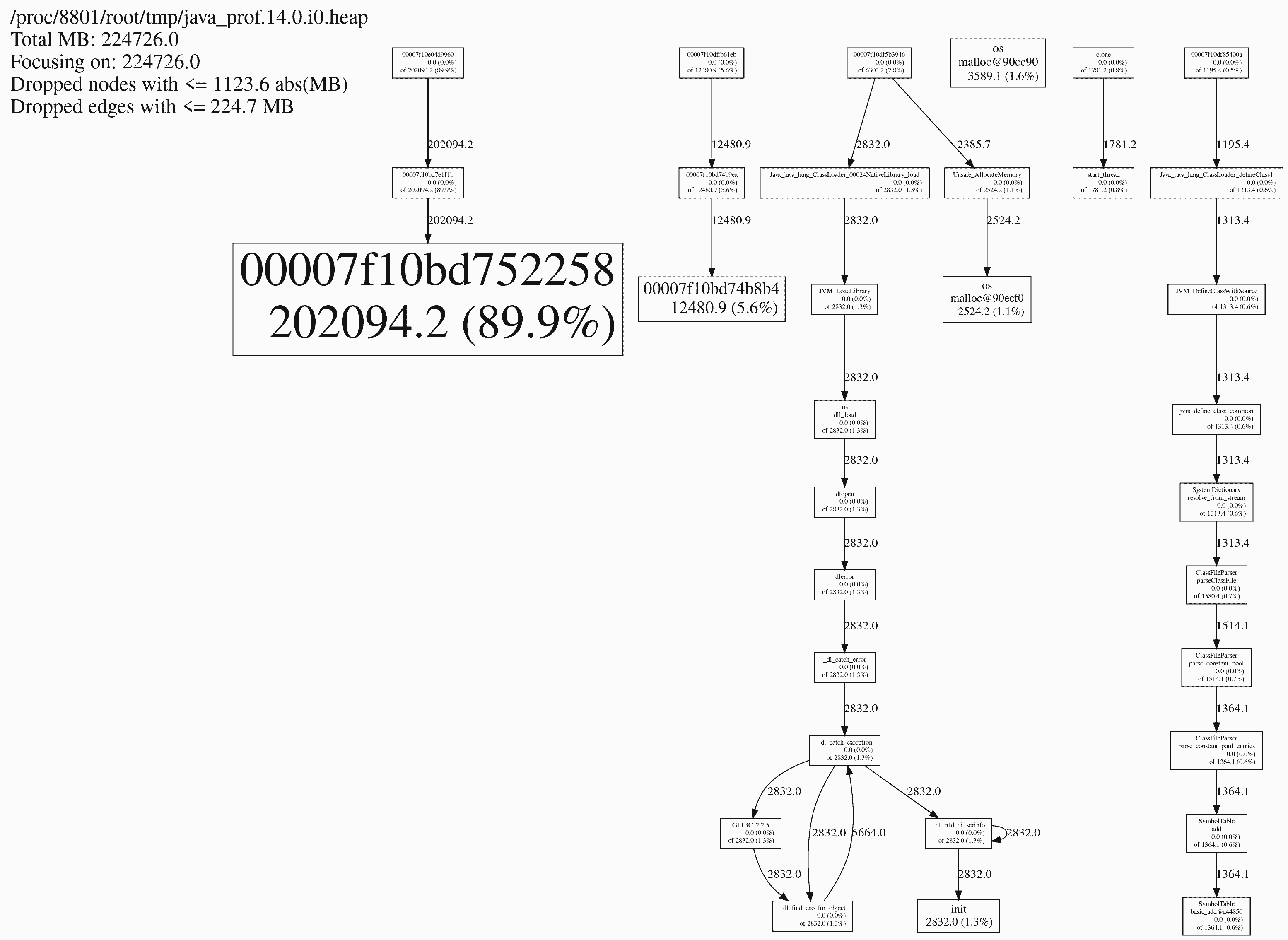
可见malloc的来源大头是一段动态代码,它不在任何一个可执行文件的内存映射区间,其来源指令地址为0x7f10e04d9960,这段代码是什么暂时不得而知,不妨gdb反汇编看看它里面究竟都是什么。
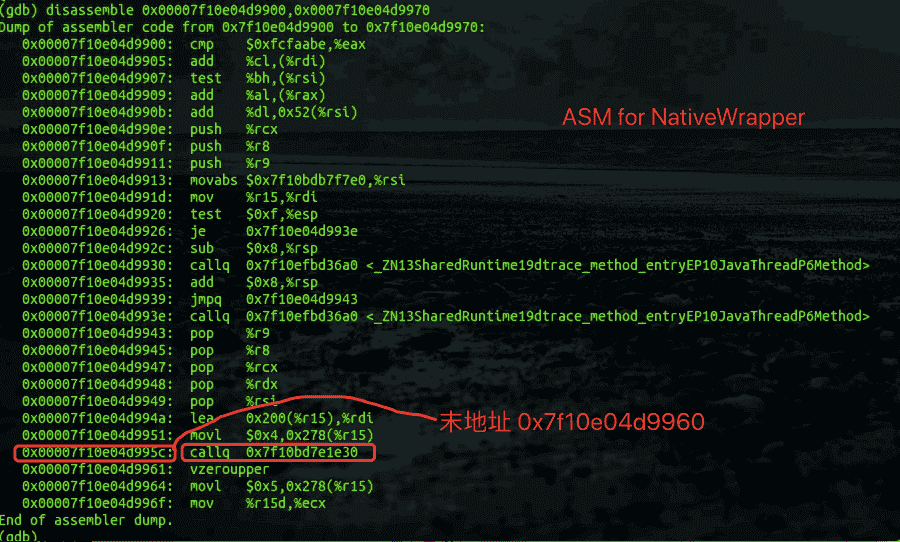
从这段汇编的特征来看,基本可以推测,这是一段所谓的native wrapper,因为Java调用native函数的原理就是动态生成一个wrapper,而wrapper最关键的指令便是红框中的call,用于跳转到真正的函数起始地址。
这时不要着急去反汇编这个函数,因为大概率它位于某个so库中,因此在进程的内存映射列表中一定能找到它的,如下图所示:
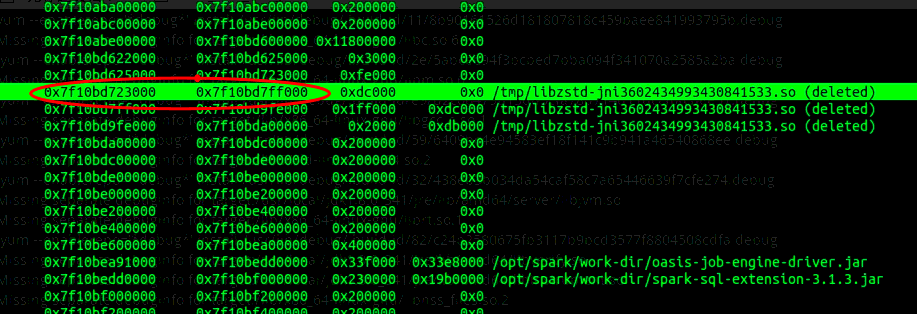
刚好就是libzstd库,问题基本定位。