基于ARCADE的架构量化分析
帮助架构师持续分析和优化软件架构,防治架构腐化(architectural decay)
架构腐化是指软件架构性能随着时间和版本的迭代而逐渐恶化或可维护性递减的现象。 软件系统在生命周期内被修改或引入新的决策时,往往产生架构腐化,这是无可避免的客观事物发展规律。
我们面临的挑战
传统的架构优化依靠架构师自身的历史经验和情怀,往往受限于公司组织结构、项目进度、个人精力等
随着公司组织结构日趋庞大,研发人员数量急剧上升,业务迭代速度越来越快,软件架构将逐步失控
由于缺乏数据支撑,架构优化无从下手,只能等到出现问题或故障时才会做这类优化,给服务稳定性带来了较大隐患
何谓架构量化分析
全称 Quantitative Architecture Analysis (QAA)
从静态代码层面进行软件架构还原和分析,以量化、数据化为导向,全面洞察软件架构的现状和变化趋势
这种架构分析并不会关注代码细节或代码本身的规范性(正如FindBugs的作用域),相反,它采用了全新的思路, 使用统计学和自然语言处理、聚类等机器学习的方法,挖掘蕴含在软件内部的关系和逻辑,还原并形成量化的架构视图, 输出相关量化指标,同时在这些数据基础上进行架构异味检测,帮助架构师掌控软件架构的变化并制定优化方法
学术界在这个问题领域内已经有一些具体思路和研究成果,例如南加州大学计算机分部提出了ARCADE模型(参考文档1) 即 Architecture Recovery, Change, And Decay Evaluator 目前已提供一个初级的开源实现,由于该研究较为前沿,没有太多参考资料或案例
为什么量化
原因有三
- 让自动化成为可能,解放架构师的人力消耗
- 形成明确的考核目标,杜绝模棱两可、是是而非的情况
- 让架构优化变得可衡量可持续可追踪
架构异味
架构异味(architectural smells)则是架构腐化的具体表现,其指的是在架构层次上不良设计决策的实例。 其源于对软件架构及抽象(如组件、接口等)的不恰当使用,架构异味的产生将会对系统的可理解性、可测试性和可复用性产生负面的影响 而之前的相关研究多依靠个人经验,缺乏对其影响的实例验证,学术界经过系统性研究总结出下面17个类别,如下图所示
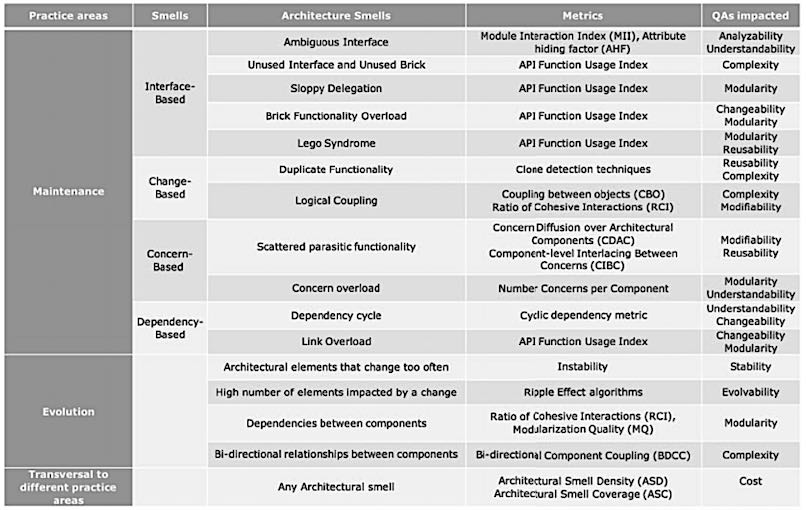
ARCADE模型结构
该模型由三大核心部分组成:架构还原、变化识别、异味识别
抽象定义
-
关注点:经过一定的自然语言统计分析推算出当前代码的主题(通常是具备业务含义的词汇,例如“交易订单”)
-
实体:由接口、链接、耦合关系三者组成,这里说的接口在Java中指Class和Interface
-
组件:由一组实体和实体所关联的关注点T的多项式概率分布组成
-
链接、耦合:由源(src)和目标(dest)实体构成
架构还原
指的是从实现构件中恢复系统体系结构的过程,而常见的实现包括源代码、可执行文件和.class文件等 我们用图表示软件体系结构、用结点表示组件、用边表示依赖关系和逻辑耦合
架构还原有三种方法,如下所示,目标都是将代码进行聚类分析,以形成组件和关系
ACDC
基于理解驱动的聚类算法 Algorithm for Comprehension-Driven Clustering,侧重于组件
常见模式如下
- 位于同一代码文件 / 目录中
- 属于系统树形结构中的叶子实体,即相互无依赖但提供类似的功能
- 被大部分子系统访问,即通用支持性功能(如工具类)
- 分发器,即由该实体出发访问大量其它子系统
- 支配器,即两个实体相互访问过程中必须经过的中间某个实体|
ARC
基于主题的架构还原,侧重于关注点,通过代码中的词语来检测当前代码的主题(topic)或关注点
主要使用基于统计模型的LDA自然语言处理算法
将代码进行聚类处理
PKG
基于包的架构还原,侧重点在于包本身,一般使用基于包结构的聚类分析(无任何特殊处理),较为简单
架构还原输出三种数据:实体依赖关系表、组件依赖关系表、异味列表
架构衰退指标(decay metric)
基于上面架构还原的输出结果,经过综合运算,输出一组衰退指标,如下所示
-
RCI (Ratio of Cohesive Interactions),0-1,组件之间的交互比率,越低越好,值越高说明代码组件之间的耦合程度越高
-
Two-way dependencies,0-∞,实体间双向依赖,越低越好
-
Modularization Quality (MQ),0-∞,一种描述耦合和内聚程度的指标,越高越好,该指标的解释和算法见参考论文2
-
MQ Ratio,0-1,正规化的模块化程度,越高越好
-
avg stability,0-1,平均稳定性,越低越好,即组件、实体变化程度
架构变化分析(a2a)
简称Architecture-to-architecture (a2a),这是一个系统级别的架构相似度指标,基于架构转换的代价,指标值域[0,1](其中1表示架构完全吻合), 在数学上有着严密的定义和计算方式

其中,
Ai和Aj代表有效的架构,Aø代表空白架构(即null)
addE / movE / remE表示从架构Ai中的某个组件转换到架构Aj中的同一组件,需要对该组件内的实体进行增加、移动、删除的数量
addC / remC表示从架构Ai转换到架构Aj,对组件本身进行的增加或者删除的数量
组件重叠(cvg)
用于衡量两个架构之间的重叠程度的指标,这个指标通常用来体现架构的变化程度,指标值域[0,1] 一般使用方式是使用同一软件两个版本之间进行对比
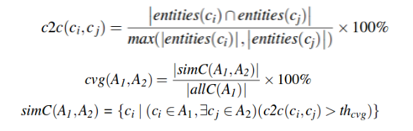
其中,entites()表示实体的集合
异味识别
基于架构还原输出的数据,分析并计算出具体代码中的异味类型,参考上文中的异味表格
异味密度(Smell Desity)
按照组件进行异味分组,从而计算出异味在不同组件中的分布情况,以及含有异味的组件比例
参考文档
- https://ieeexplore.ieee.org/document/8417151
- On the automatic modularization of software systems using the bunch tool
- Toward a Classification Framework for Software Architectural Smells
- https://ieeexplore.ieee.org/document/891477