Web应用响应平滑与RPC优化
概述
堆糖web系统主要分为两层,第一层是直接面向用户的web系统,第二层是服务中心,提供rpc服务。 长时间以来系统稳定性一直面临一些挑战,例如在高峰时期,响应曲线抖动比较厉害,rpc服务大量异常。
流量不均
首先排除流量分布不均匀的可能性。 web系统前端nginx流量分布情况,数据来自于nginx日志
**5805 192.168.*.31:8300
**5897 192.168.*.28:8300
**5565 192.168.*.40:8300
**5707 192.168.*.37:8300
**5780 192.168.*.32:8300
**5618 192.168.*.38:8300
**5735 192.168.*.33:8300
可以看出这几台web节点的流量基本一致。因此不可能是由于nginx端输入流量不均衡导致。
链路跟踪
线上系统已经全面部署了调用链路跟踪(Call Chain Tracing ,简称CCT)设施并与RPC打通,因此可以很方便的查看每一条调用链的执行情况。
从CCT日志采样,取22:38分的尖峰作为采样点,分析日志提取所有响应时间高于500ms的调用链, 下面是部分数据:
i769g8348459:743
i769g88a3602:569
i769g8bg3839:508
i769g89j9066:646
i769g83u0657:996
i769g8lr6276:771
i769g8ce1169:1146
以i769g8ce1169为例,该调用链具体情况如下:
{"token":"i769g8ce1169","target":"com.duitang.domain.repo.BlogRepo::find","depth":2,"seq":0,"startTime":1426171100990,"endTime":1426171101164,"elapsedTime":174,"parent":892538882,"self":1201934660}
{"token":"i769g8ce1169","target":"com.duitang.domain.repo.LikeRepo::queryLikeIdByBlogId","depth":2,"seq":1,"startTime":1426171101164,"endTime":1426171101198,"elapsedTime":34,"parent":892538882,"self":73422346}
{"token":"i769g8ce1169","target":"com.duitang.domain.repo.AlbumRepo::findNextBlog","depth":2,"seq":2,"startTime":1426171101198,"endTime":1426171101221,"elapsedTime":23,"parent":892538882,"self":686128032}
{"token":"i769g8ce1169","target":"com.duitang.domain.repo.AlbumRepo::findPrevBlog","depth":2,"seq":3,"startTime":1426171101221,"endTime":1426171101234,"elapsedTime":13,"parent":892538882,"self":910031776}
{"token":"i769g8ce1169","target":"com.duitang.domain.repo.BlogRepo::isFavorited","depth":2,"seq":5,"startTime":1426171101235,"endTime":1426171101355,"elapsedTime":120,"parent":892538882,"self":376301093}
{"token":"i769g8ce1169","target":"com.duitang.domain.repo.TagRepo::queryTagByBlogId","depth":2,"seq":6,"startTime":1426171101355,"endTime":1426171101502,"elapsedTime":147,"parent":892538882,"self":1067326435}
{"token":"i769g8ce1169","target":"com.duitang.domain.repo.BlogRepo::queryLatestForwardAlbumId","depth":2,"seq":7,"startTime":1426171101502,"endTime":1426171101505,"elapsedTime":3,"parent":892538882,"self":1201076079}
{"token":"i769g8ce1169","target":"com.duitang.domain.repo.AlbumRepo::queryAlbum","depth":2,"seq":8,"startTime":1426171101505,"endTime":1426171101510,"elapsedTime":5,"parent":892538882,"self":708810073}
{"token":"i769g8ce1169","target":"com.duitang.domain.repo.AlbumRepo::queryCoverOne","depth":2,"seq":9,"startTime":1426171101510,"endTime":1426171102136,"elapsedTime":626,"parent":892538882,"self":217889797}
{"token":"i769g8ce1169","target":"com.duitang.views.napi.blog.BlogApi::detail","depth":1,"seq":0,"startTime":1426171100990,"endTime":1426171102136,"elapsedTime":1146,"parent":0,"self":892538882}
这条调用链中的RPC调用RT差异极大,部分达到几百毫秒级别,毫无疑问该次RPC调用服务端耗时时间很长,但是这么长的时间都用到什么地方了?
一般来说服务端时间可以分为三个部分(Latency):
- L1,client到server的网络延迟。
- L2,server拿到请求到请求真正被处理的延迟。
- L3,server端真正处理时间。
按照正常人类思维,首先想到L3应该是最有可能的。得益于CCT在RPC层面已经打通,我们可以很方便的追踪当前这次请求在服务端逻辑处理的时间。但是经过CCT日志筛选,在服务端并没有发现这条调用链,那么只有一种解释就是服务端逻辑处理时间未超过基线时间(当前基线是20ms,也就是说如果处理时间小于这个值,CCT不会记录日志)。
所以L3的可能性就被排除。剩下L1和L2,前者我们已经怀疑很久,后来加上网络监控,即在每次rpc调用失败时,主动监测一下服务端节点是否能ping通(InetAddress.isReachable() ),发现网络并未像想象中的那么糟糕,还算是可以接受,完全不足以造成这么大的延迟。
那么L2究竟是什么情况?
要研究这个问题还是得从源头看起,也就是rpc调用的处理机制。目前rpc采用线程池来分发请求,每个rpc请求到达server端后会立刻进入线程池排队等待,这里的线程池采用的是JDK标准的ThreadPool, 其中,coreSize=5;maxSize=100;按照下述配置进行测试:
配置A
producer: 50个线程 每个线程提交5000个task(总共50*5000=250000)
每个task提交时间间隔3ms(模拟网络延迟)
consumer: ThreadPool (coreSize=100,maxSize=200)
task: 模拟平均耗时10ms(0~20ms浮动,随机取值)
输出延迟时间落在每个区间的比例,其中err是提交失败数:
err:0
0~99 69
100~199 4
200~299 5
300~399 4
400~499 4
500~599 4
600~699 5
700~799 1
可以看到69%的task都在99ms以内响应。
配置B
其它保持不变,coreSize=150 err:0 0\~99 100
coreSize对性能有着较大影响,因此决定根据业务系统实际响应情况来调整。 尽管如此但是是否仅修改线程池就能解决响应抖动的问题?
一般来说rpc服务端响应时间取决于下面几点:
- 服务集群本身的服务能力
- 服务集群负载均衡
- 单个节点限流
整个服务集群能提供的服务是有限的,如果请求量超出其阈值则集群服务能力会急剧下降,类似于拒绝服务攻击的效果。探测集群最大的服务能力并不是一件容易的事情,常规可以使用全链路压测的方式,将真实的流量打到测试集群,并实时监控运行情况,反复迭代后可以获取粗略值。
服务集群是由一个个的节点组成,每个节点可能由于机器配置、运行环境的不同而各有差异,因此负载均衡是很重要的一点。我们的rpc服务均衡采用Adapted WRR(Weighted Round-Robin)算法,这个算法分为两部分,一部分是权重自适应,另一部分是标准的WRR(核心思想取自LVS),所谓权重自适应就是根据服务端错误率来动态调整权重。
算法具体细节:
* 每个节点初始权重(WT)都是100
* 当某节点发生调用时,调用数自增1
* 当某节点调用出错或超时时,错误数自增1
* 每间隔 T ms 计算此时间段内的错误率,ER = 错误数 / 调用数
* 若错率大于0则调整权重,WT = WT' - ER * 100
* 当错率高于预设的阈值时,WT = 0,相当于直接剔出该节点
* 若错率为0则WT = (WT + 1)*k,即缓慢恢复权重;
这里的k是一个恢复系数,如果增大此值,恢复速度将加快,反之亦然 另外如果动态新加入了节点,则重现计算所有节点权重,这一部分主要由服务发现模块来完成。
节点本身服务能力也是有限的,为了避免雪崩就需要做限流,对于超出限制的请求直接返回不再处理,由rpc客户端来决定是否重试。
限流通过两个方式来实现,一个是控制等待队列长度;二是控制等待的时间。例如在Java的ThreadPool中的workQueue,将此队列长度限定在某个值,超出此长度的任务提交将会失败。当任务提交后,给其生成一个时间戳记录当前时间;一旦任务开始执行,再次计算执行开始时间和提交时间的差值,一旦高于阈值就立刻返回,不再继续进行真正的逻辑处理,并给上层应用抛出过载的异常,以便应用根据不同的异常执行不同的错误策略。
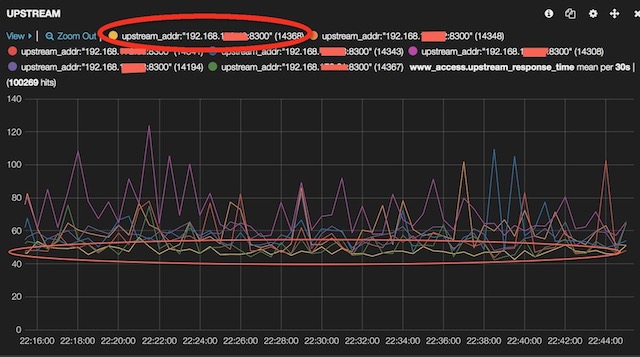
基于这三点出发,我们对整个架构做了大量优化,效果是比较明显的,如下图,黄色那条线是优化过的节点响应曲线,可以看到在高峰时期响应曲线非常平稳,相反其它未做优化的节点抖动较为厉害。